Overview:
-
✔️ Conduct the first systematic study on compositional text-to-video generation and propose a benchmark, T2V-CompBench.
✔️ Evaluate diverse aspects of compositionality with carefully designed metrics, covering 7 categories with 700 text prompts.
✔️ Propose evaluation metrics specifically designed for compositional T2V generation, verified by human evaluations: MLLM-based evaluation metrics, Detection-based evaluation metrics and Tracking-based evaluation metrics.
✔️ Benchmark and analyze 20 text-to-video generation models, highlighting the significant challenge of compositional text-to-video generation for current models and aiming to guide future research.
Introduction
Evaluation Metrics
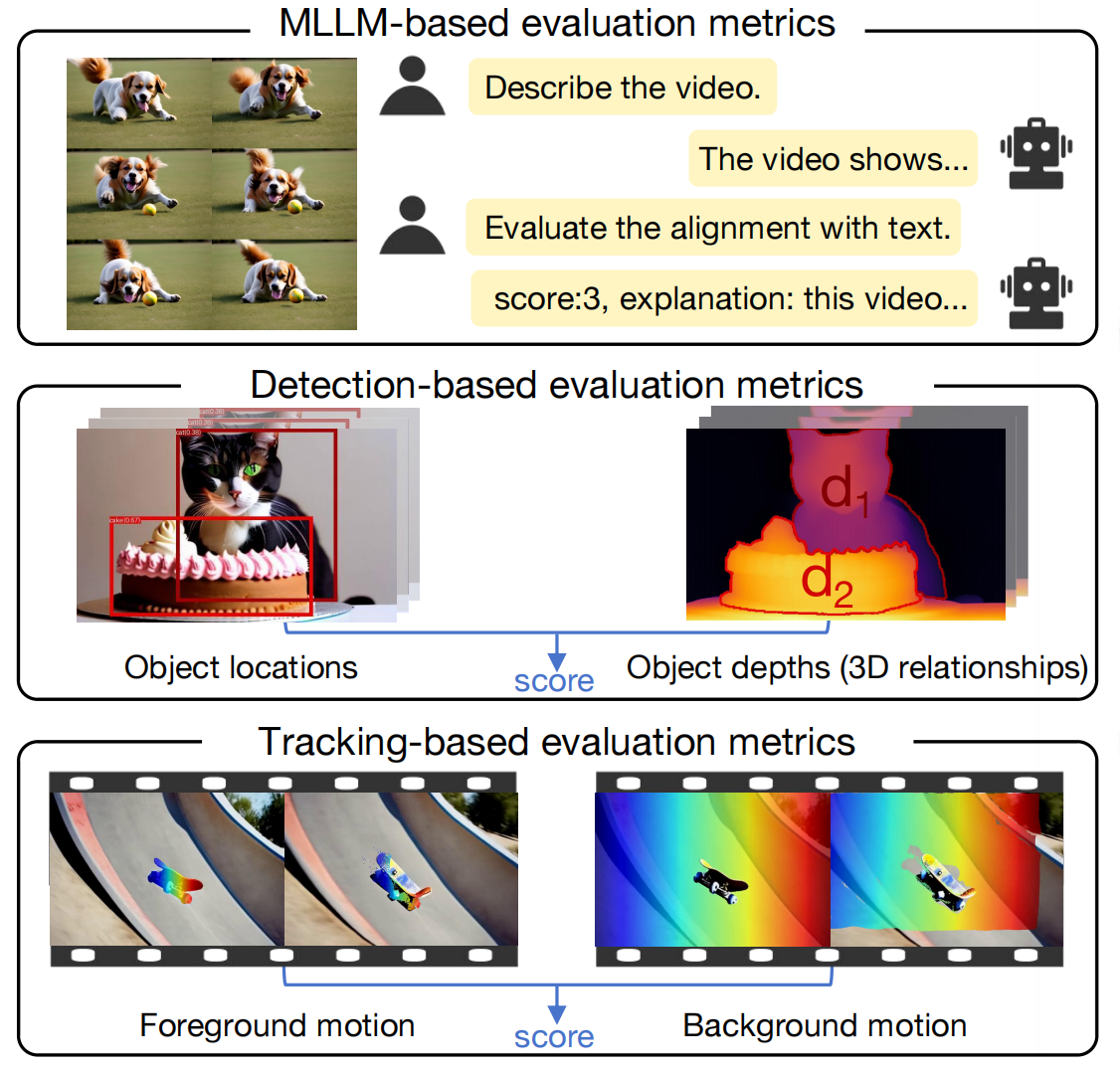
MLLM-based evaluation metrics for consistent and dynamic attribute binding, action binding and object interactions.
Detection-based evaluation metrics for spatial relationships and object interactions.
Tracking-based evaluation metrics for motion binding.
Evaluation Results




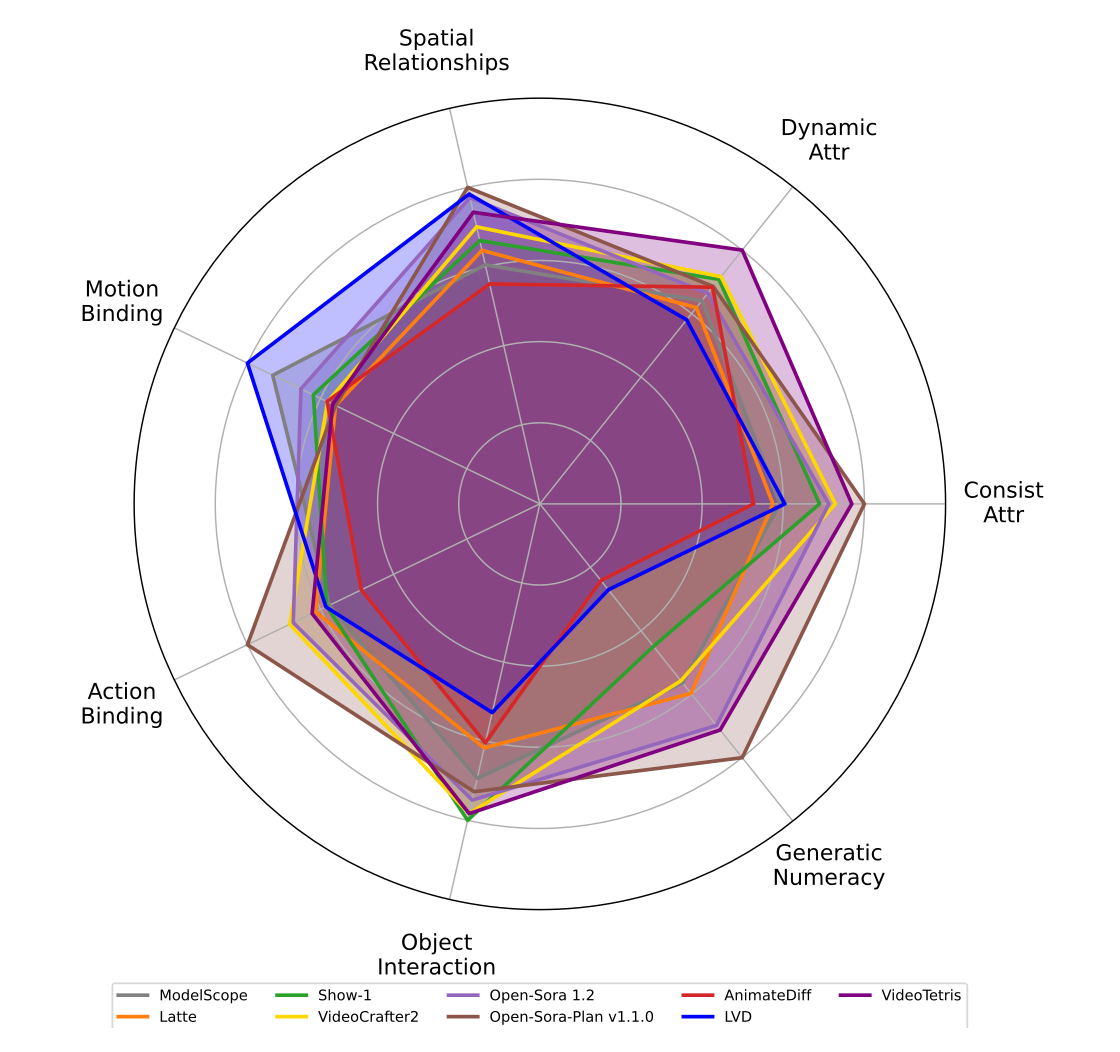
Benchmarking open-sourced T2V Models with a radar chart.
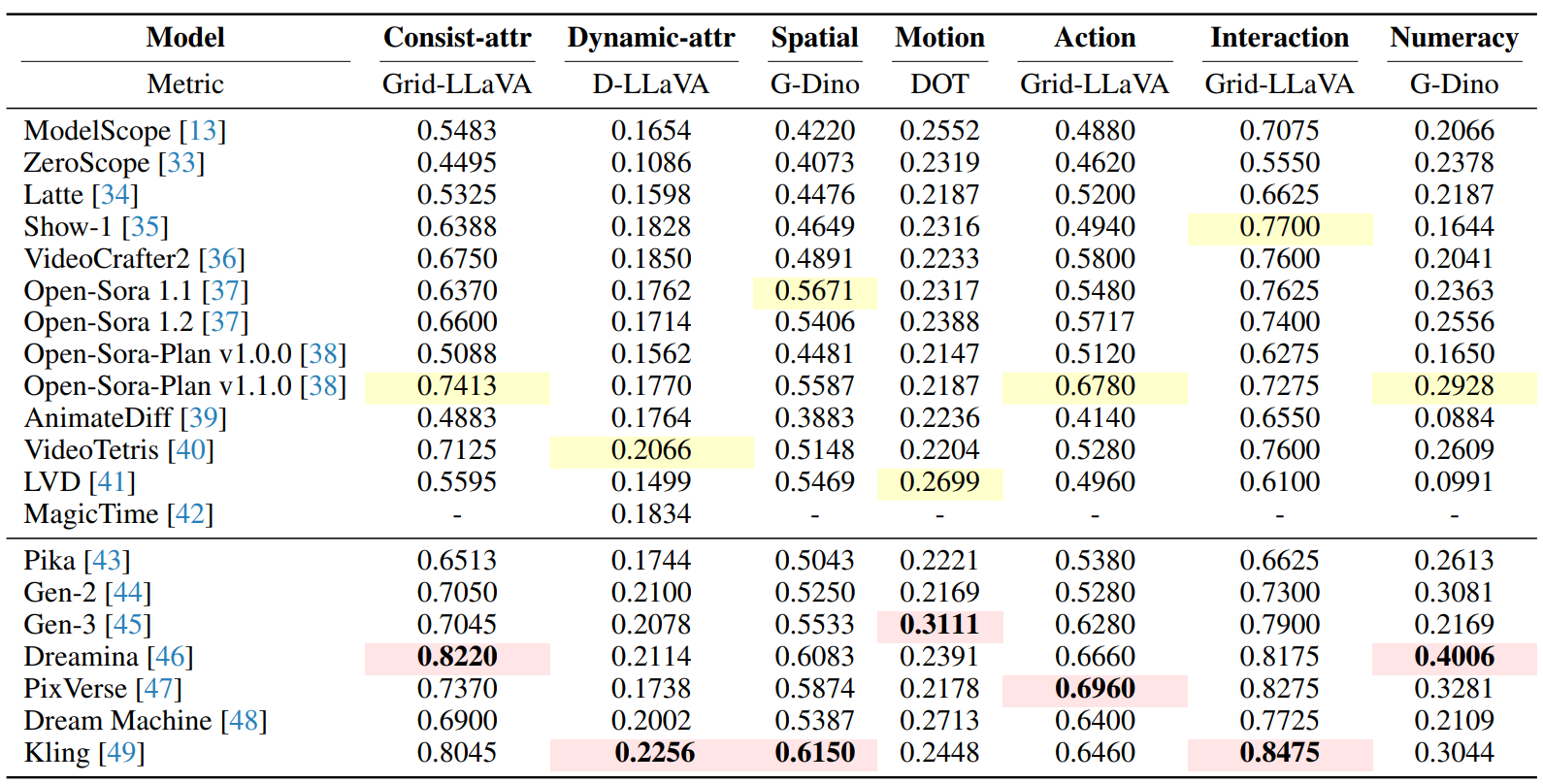
T2V-CompBench evaluation results with proposed metrics for 20 T2V generation models (13 open-source models and 7 commercial models).
Bold stands for the best score,
red indicates the best score across 7 commercial models,
yellow indicates the best score across 13 open-sourced models.
Bibtex